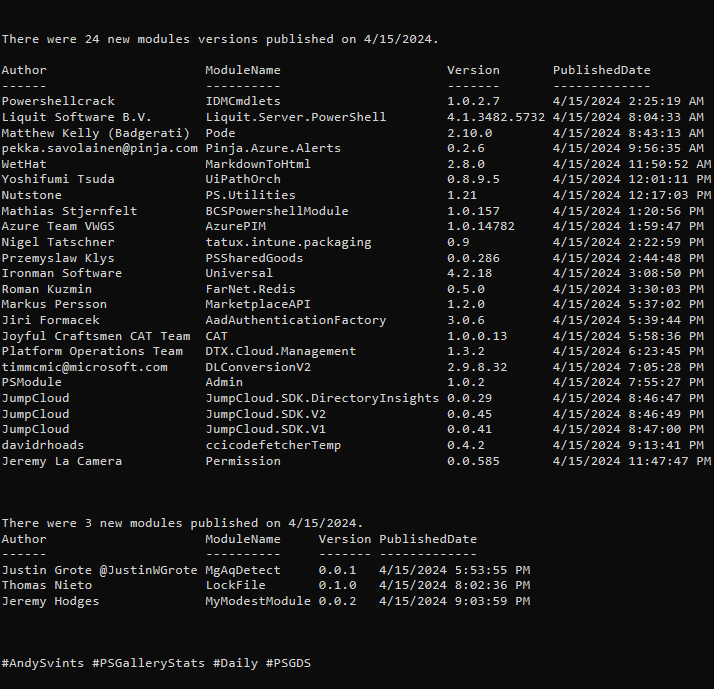
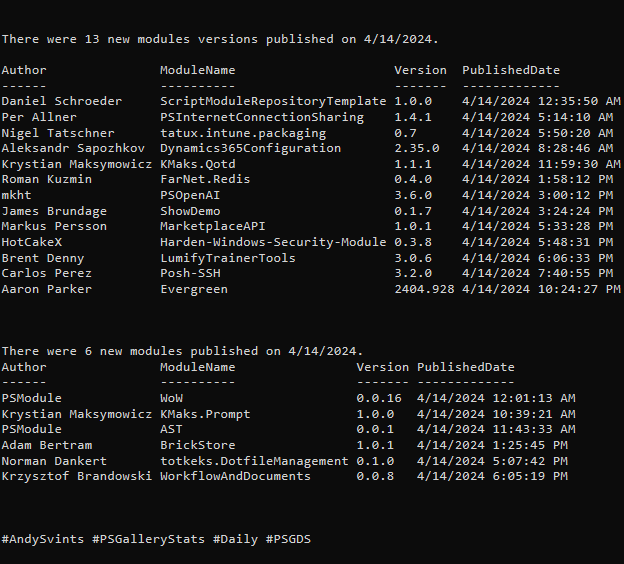
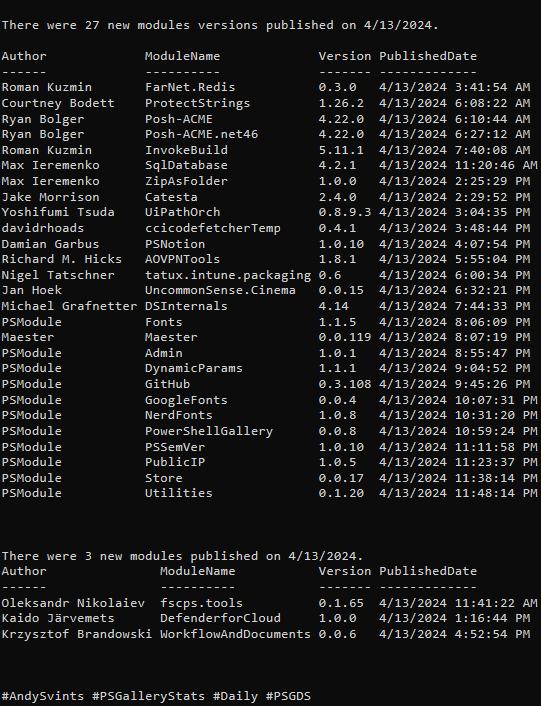
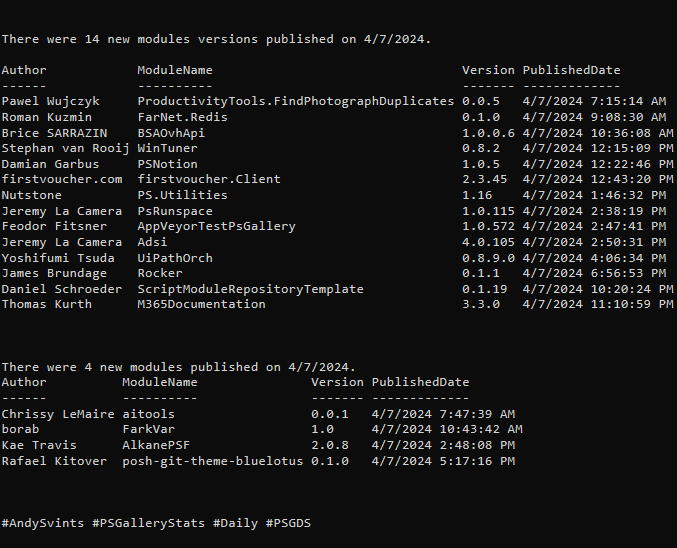
This is the 5th post from the Data Manipulations with PowerShell series, where we are diving into the specific phase of data operations processes and apply/use PowerShell along the way.
Previous posts:
- Empower your Data Retrieval with PowerShell
- Make your Data Processing more efficient with PowerShell
- Data Transformation Made Easy with PowerShell – Part 1, Part 2

Data Analysis phase is used to uncover meaningful patterns and draw conclusions. It involves using various statistical and computational techniques to extract insights and knowledge from large and complex datasets. Main aspects of data analysis:
- Descriptive Analysis
- Inferential Analysis
- Predictive Analysis
- Prescriptive Analysis
- Data Mining
Out of the Box
As usual, if you know what you need to do and understand the process and steps end to end, PowerShell out of the box cmdlets got you covered.
Descriptive Analysis
The gist here is in calculating basic statistical measures to summarize and understand the characteristics of the data. Items like mean, median, mode, standard deviation, or range. In addition, frequency and Interquartile Range (IQR) are also part of the descriptive data analysis.
For our first example here, we are going to utilize Measure-Object cmdlets with -AllStats parameter to our Age column.

$Dataset4.Age | measure-object -AllStats
In the next example, we are going to look into frequency. This can be accomplished with Group-Object cmdlet. To be honest this is my favorite approach with any data set. This is very easy and pretty informative. First, I am looking at the list of columns/properties and then run Group-Object on specific properties.

$Dataset4 | Group-Object -Property Area | Select-Object Name,Count | Sort-Object Count -Descending
In addition, one more useful characteristic of the data, that falls under Descriptive data analysis is Interquartile Range (IQR). It is the range between the first quartile (Q1) and the third quartile (Q3) in a dataset.

$sortedSalary = $Dataset4.Salary | Sort-Object $count = $sortedSalary.Count $lowerQuartile = $sortedSalary[([int]($count * 0.25))] $upperQuartile = $sortedSalary[([int]($count * 0.75))] $IQR = $upperQuartile - $lowerQuartile
Inferential Analysis
This technique involves drawing conclusions, making predictions, or generalizing results about a population based on a sample of data. Here we are doing things like hypothesis testing, confidence interval and variance. All of the calculations are based on the mathematics, you need to have decent understanding of concepts and well thought the process and what you need to get out of your data.
Let’s look closer to calculations with examples. In this example we will take a stab into Confidence Interval. From the definition it is – “range of values that provides an estimated range of plausible values for an unknown population parameter”. The validity of the calculation highly depends on the sample size and population standard deviation. In the following example, I am assuming that the only thing we possess is the data sample and we do not know anything about population.
In this case, the formula is the following:

Critical value t is obtained from the t-table, which is the reference table that lists critical values. They can be freely downloaded from Internet. OK, so we got distracted a bit with all the definitions and formulas, let’s reiterate the input values for our example.
Dataset (aka data sample) and we are focusing on the Salary column.

Mean, size and standard deviation of the Salary.

Desired confidence level is 0.9 (90%) (just because I want so =P ), degrees of freedom is 29 (size – 1), level of significance is 0.1 (1-confidence level) and the critical t value – 2.756 (based on the t-table).
Let’s put it all together:

$ConfidenceIntervalP=[System.Math]::Abs($mean+$t*($standardDeviation/[System.Math]::Sqrt($size))) $ConfidenceIntervalM=[System.Math]::Abs($mean-$t*($standardDeviation/[System.Math]::Sqrt($size)))
I’ll have to admit I’ve got too excited and sidetracked by Math and Statistics and probable bored you to death… So, no more “nerding” on the Math side and let’s move on.
Excel & Power Bi Integration
Integration with Excel and Power BI is right on the edge between Data Analysis and Data Visualization, as those two tools have a lot of capabilities for both phases. I will just briefly mention that for Excel manipulations with PowerShell there is an awesome ImportExcel module and for PowerBI – MicrosoftPowerBIMgmt.
Community Provided
Modules with *analysis* in the name, tags and/or description – 38.
- ImportExcel by Douglas Finke (aka dfinke) – work with Excel spreadsheets, without Excel.
- Statistics by Nicholas Dille – Statistical analysis of data in the console.
- PowerBIPS.Tools by DevScope – collection of very useful tools for Power BI.
Summary
As you can see, PowerShell offers a powerful approach for detailed data analysis. It is based on the integration of mathematical and statistical concepts with PowerShell’s scripting capabilities. By incorporating math formulas and statistical techniques, PowerShell helps to uncover meaningful insights and patterns from complex datasets. Through the holistic approach, analysts can identify and extract valuable patterns and with the help of the visualization communicate their findings with clarity and impact.
Data icons created by Freepik – Flaticon.
Thanks a lot for reading.