
This is one of the posts from the PoweshellIT series in which we get common and sometimes not so common usecases and try to simplify/automate them using PowerShell.
Today’s Use Case
Identify identical files(twins) in the folder. Not just with same metadata (file name, author, file size, timestamps) but truly identical files which have the same content.
Infrastructure overview

Disclaimer: We will be just finding duplicate files and reporting result to user. What to do with the duplicates(remove, keep both, ignore) it is totally up to user.
Context
The idea is to compare file contents pretty quickly. We do not need to compare file names and timestamps just to identify two files with identical content. The fast and reliable way to identify file twins (with identical content) is to use hashing.
Hashing or hash function is a one way function which generates fixed size output called hash value based on the input of different length.
Being a one way function means that it is practically infeasible to invert.
And luckily for us PowerShell has a built in cmdlet Get-FileHash. (“Oh how convenient“).
This cmdlet “computes the hash value for a file by using a specified hash algorithm”. Default Hashing algorithm is SHA256 which is a member of SHA-2 family and is using 256bit key to compute the hash value.
We will cover two variations of our use case:
- Find Duplicates within the folder
- Find duplicate for a specified file within the folder
References:
https://en.wikipedia.org/wiki/Hash_function
https://en.wikipedia.org/wiki/Cryptographic_hash_function
https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/get-filehash?view=powershell-7
https://en.wikipedia.org/wiki/SHA-2
Challenges
- Acceptable performance as computing hash values for high number of files will require compute resources;
- Once the duplicates are found provide meaningful output which will not confuse users;
Proposed solution
Simple and elegant PowerShell function which will accept path to folder where duplicates(twins) should be found. Also an additional(optional) parameter, a path to file which should be considered as baseline and identify any of duplicates of it.
Pseudo code
#Find Duplicates within folder Get List of files in the Directory Generate hash values for each file Compare hashes and identify any duplicates #Find Duplicate of a file within folder Generate hash value for a BaseFile Get List of file in the Directory Generate hash values for each file Compare baseline hash to Directory files hash values and identify duplicates
It has been wrapped into PowerShell module called FileTwin.
Module contains one function called Find-FileTwin.
Find-FileTwin
Find file duplicates in the specified folder or look for a duplicate of the provided file within the specific location.
EXAMPLE
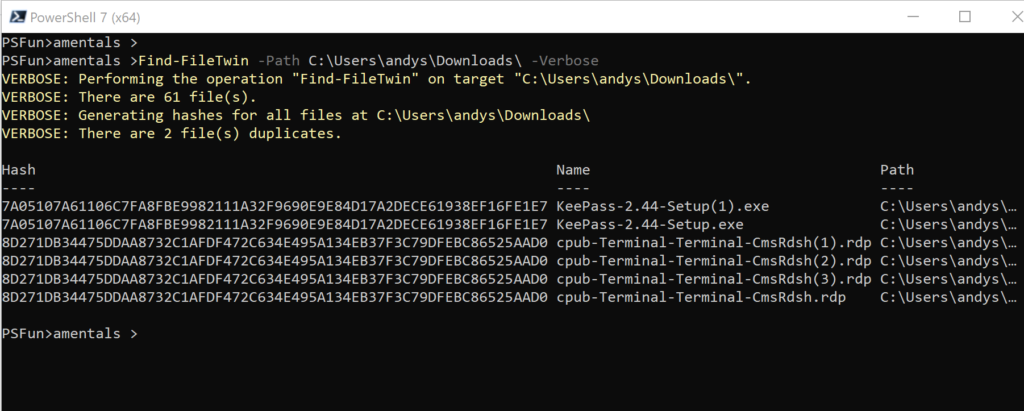
Identify duplicates in the directory.
Find-FileTwin -Path C:\Users\andys\Downloads\ -Verbose
EXAMPLE
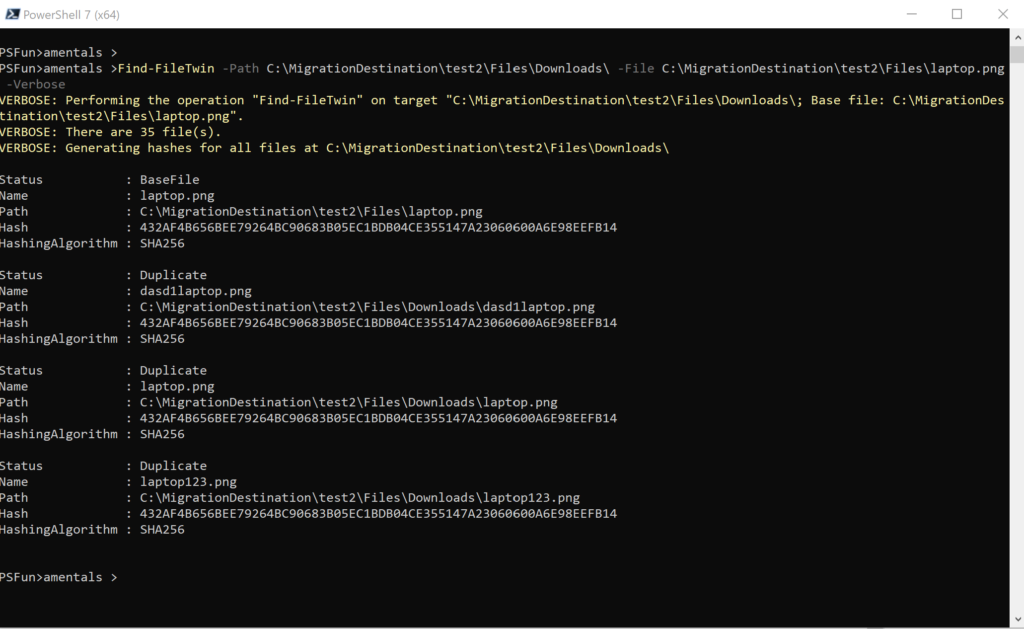
Find duplicate for a specific file within directory.
Find-FileTwin -Path C:\MigrationDestination\test2\Files\Downloads\ -File C:\MigrationDestination\test2\Files\laptop.png -Verbose
All of the source code is available in PowerShellIT repository on the GitHub.
Thanks a lot for reading.

Icons made by Eucalyp & Good Ware & Freepik from www.flaticon.com
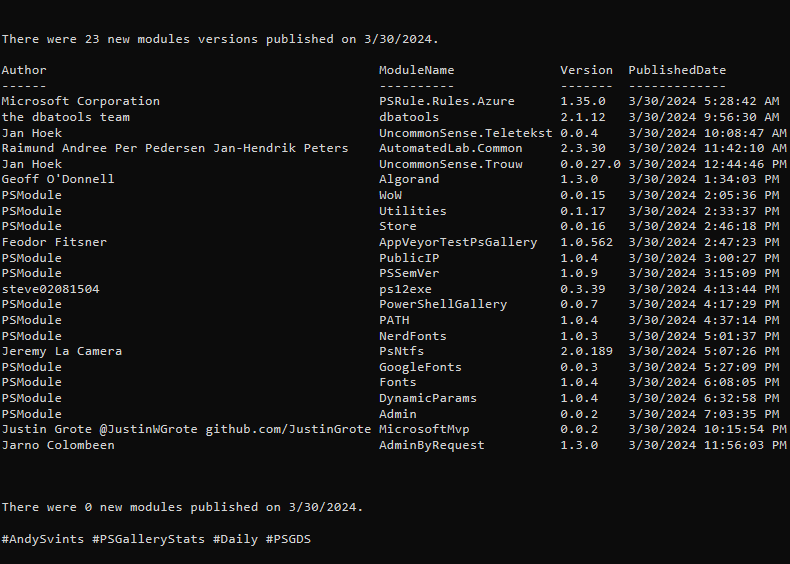
You can save a substantial amount of time by picking out only those files that are the same length as the target file before hashing. Since it’s impossible for files of different lengths to be identical you eliminate a lot of mismatched files before you begin hashing, reducing the number of hashes you need to perform. My application has me scanning thousands of files against each other, I have no idea which files might have twins. I use a trivial script that groups all the files by length then selects those groups that have two or more members to be hashed. I haven’t measured it, but the time difference between my current script and the previous “hash everything” scripts I tried is massive. It pulled over 700 duplicates out of 8,000 files in a matter of seconds earlier this evening. The other scripts had me looking around the room waiting for something to happen. And I’m running an ancient Intel Q9650 CPU, getting anything done in seconds is impressive.
You are right. Your approach is smarter and much faster!
Thanks a lot for sharing, I really appreciate it.